![]()
![]()
![]()
![]()
DoubleMLDeep: Estimation of Causal Effects with Multimodal Data
Causal Inference and Missing Data Group at Inria
22.04.2024
Motivation
- Causal Inference mainly relies on tabular data
- In a lot of applications additional unstructured data is available
- We consider multimodal data as confounders
- Applications in Marketing, Medicine / Health, Finance, ….
- Price elasticity of demand
- Estimation of treatment effects conditioning on X-ray images
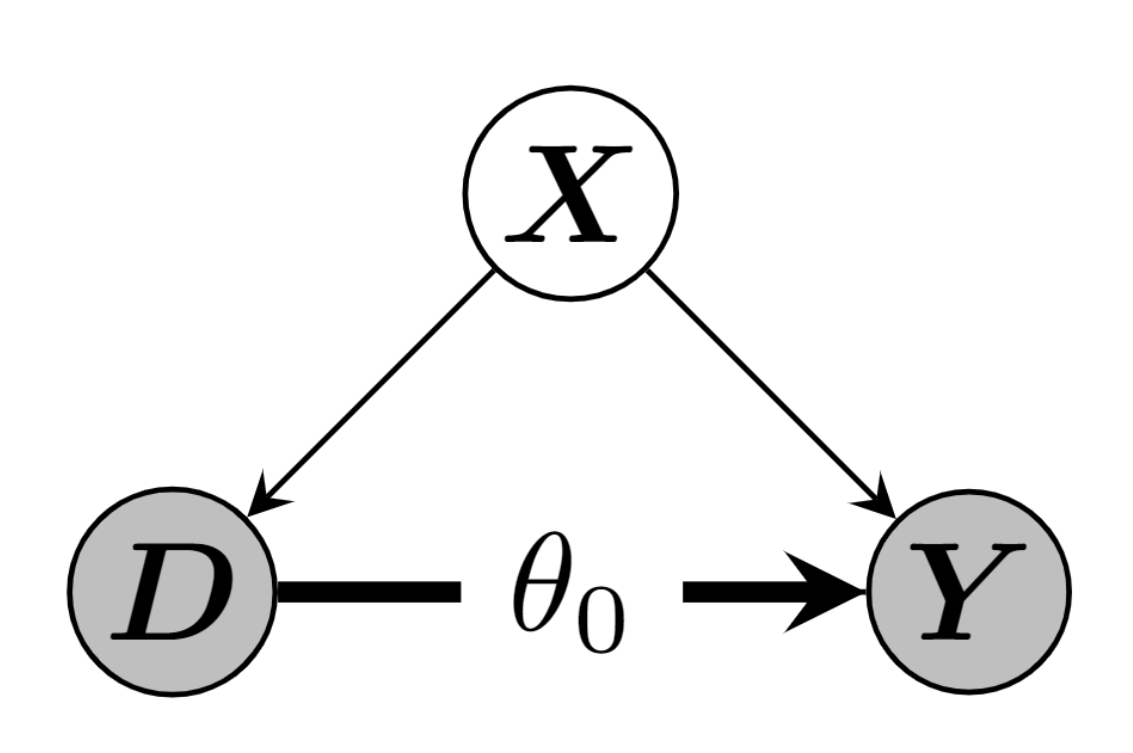
Motivating Example - PLR
Partially linear regression model (PLR)
\[ \begin{align} Y &= \theta_0 D + g_0(X) + \varepsilon, & \mathbb{E}[\varepsilon | X, D] = 0 \label{eq:plr1} \\ D &= m_0(X) + \vartheta, & \mathbb{E}[\vartheta | X] = 0 \label{eq:plr2} \end{align} \]
with
- \(Y\) - outcome variable
- \(D\) - policy/treatment variable
- \(X = (X_1, \dots)^T\) - vector of additional controls
- \(\varepsilon\), \(\vartheta\) - stochastic errors
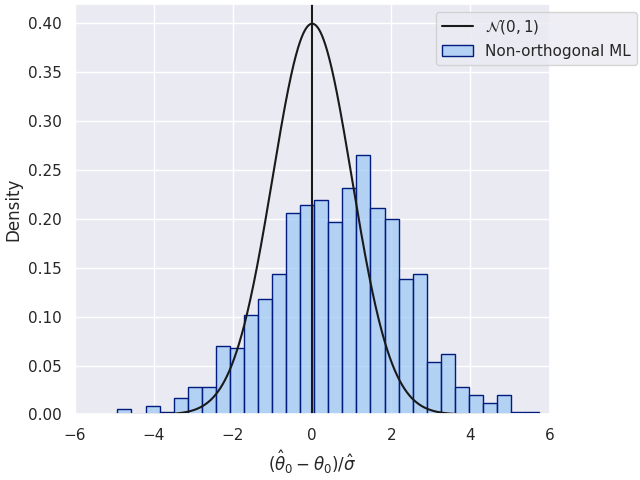
Motivating Example - Regularization Bias
- What if we simply plug-in ML predictions \(\hat{g}(X)\) for \(g_0(X)\) into \(Y = \theta_0D + g_0(X) + \varepsilon\)?
Motivating Example - Orthogonalization
Frisch-Waugh-Lovell style approach: \(\theta_0\) can be consistently estimated by partialling out \(X\), i.e,
- Predict \(Y\) and \(D\) by \(\mathbb{E}[Y|X]\) and \(\mathbb{E}[D|X]\), obtained using ML methods
- Residualize \(\tilde{Y} = Y - \mathbb{E}[Y|X]\) and \(\tilde{D} = D - \mathbb{E}[D|X]\)
- Regress \(\tilde{Y}\) on \(\tilde{D}\) to obtain \(\hat{\theta}\)
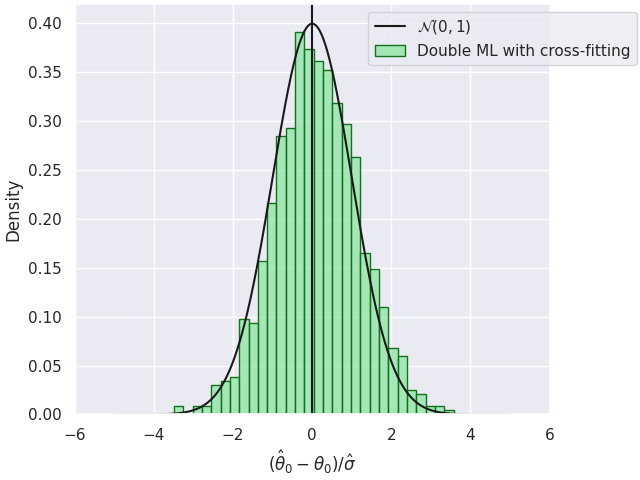
DoubleML Deep - Motivation
- Use multimodal data (text and images) additionally to conventional tabular features
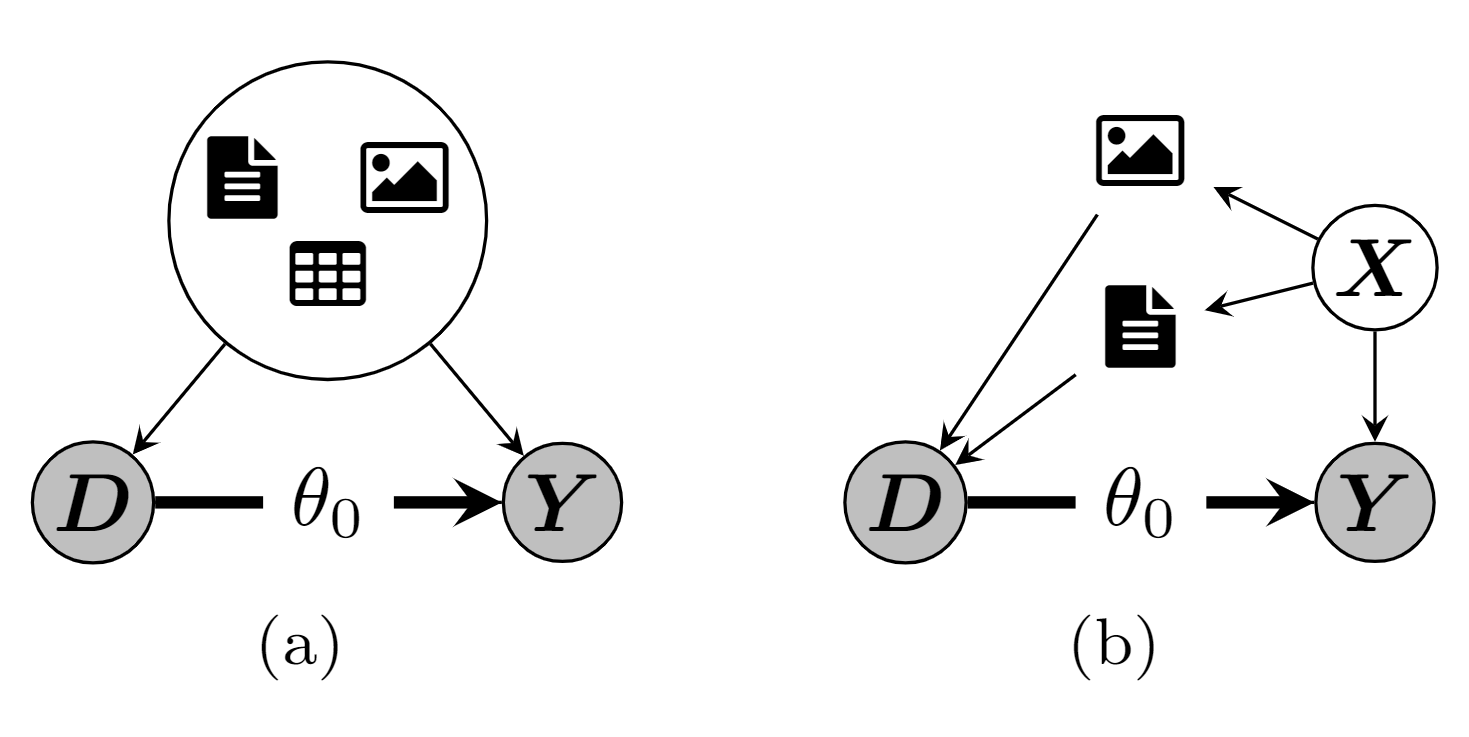
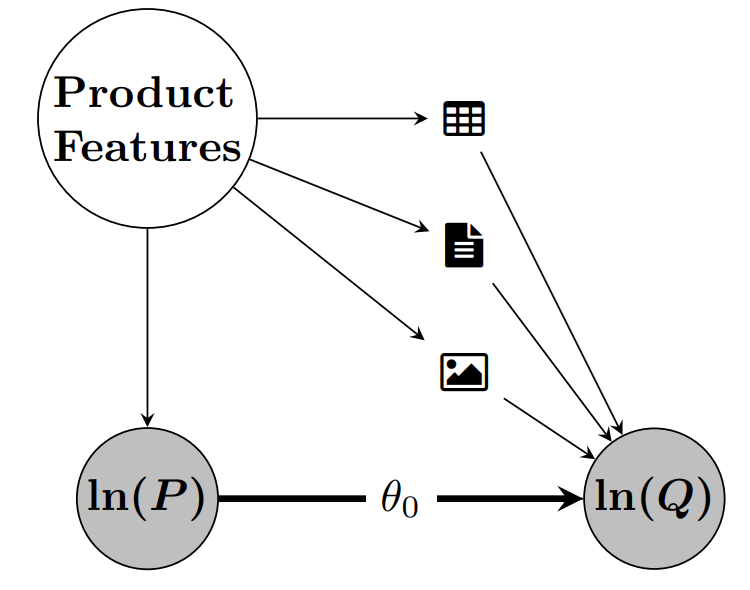
DoubleML Deep - Module Structure
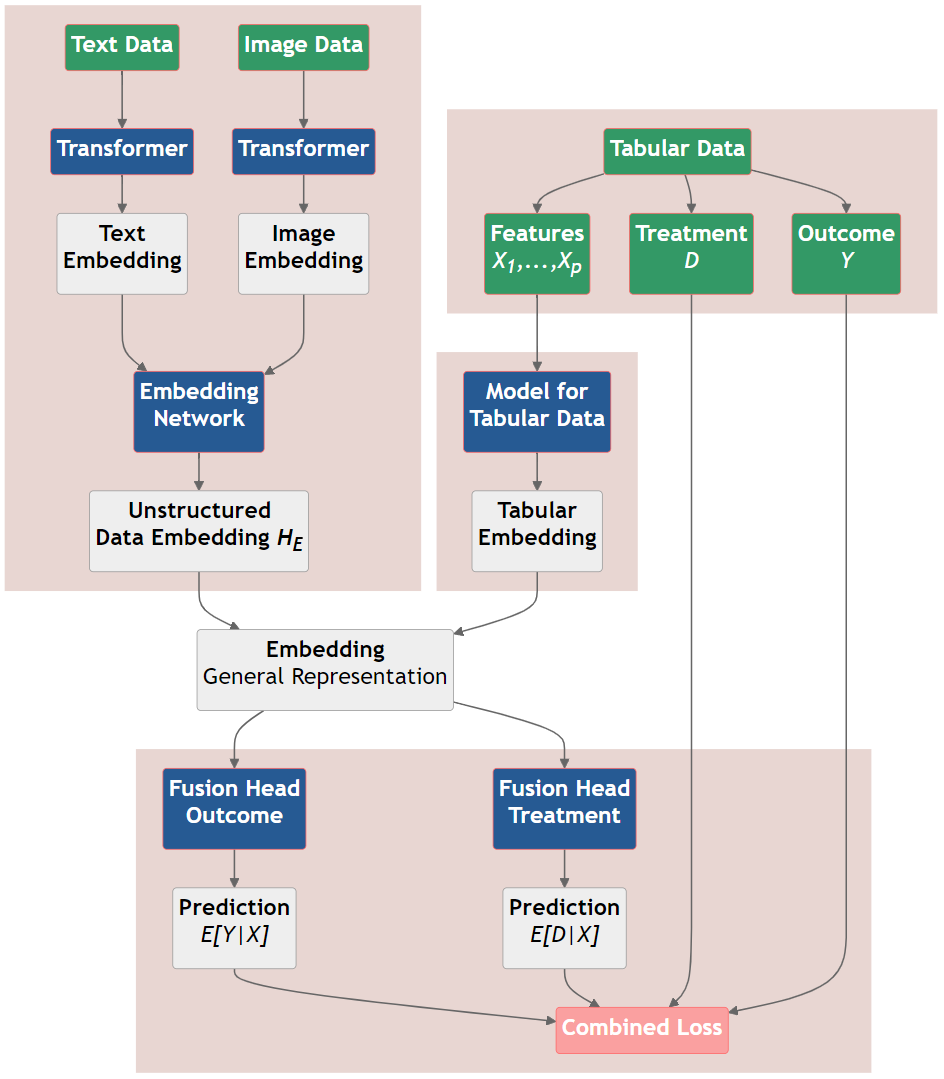
DoubleML Deep - Workflow
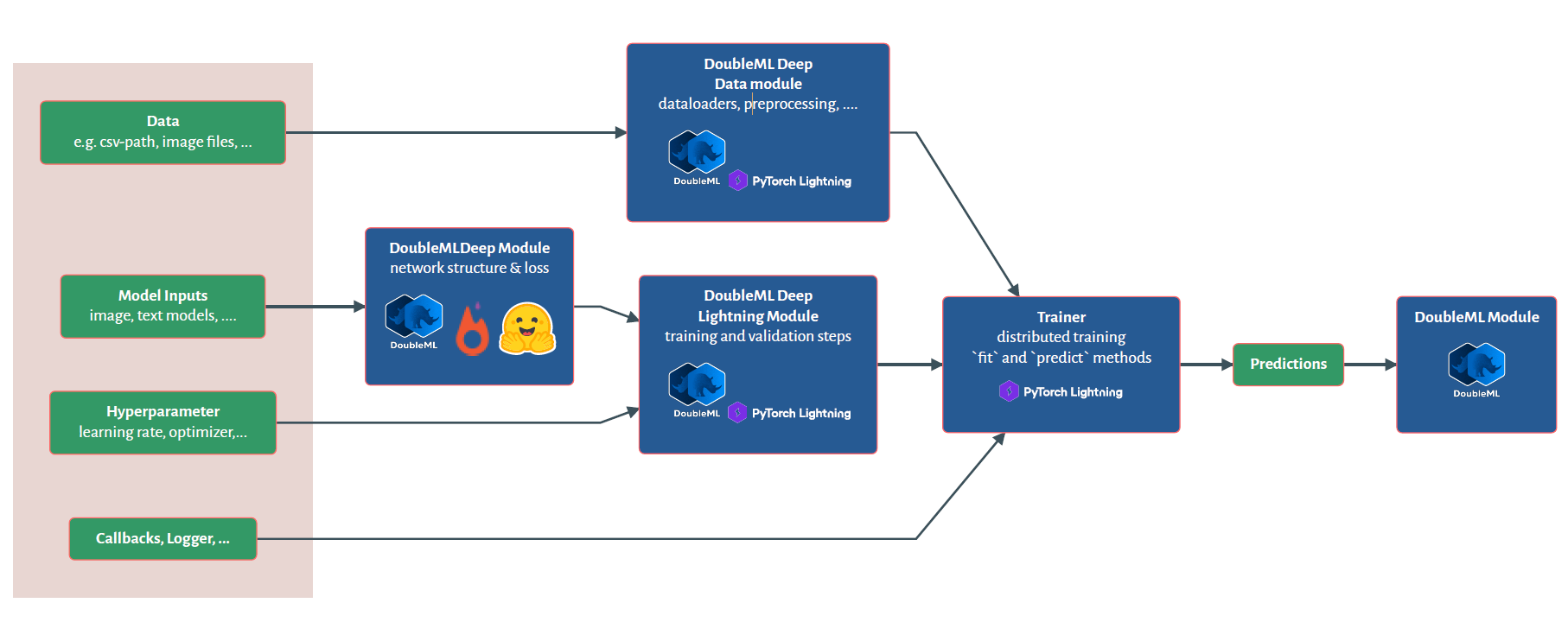
Challenges
- Due to the negative sign and the additive structure, the confounding effect will ensure that higher outcomes \(Y\) occur with lower treatment values \(D\), creating a negative bias
- The independence of all three original datasets and the additive negative confounding results in a negative bias even if we only control for a subset of confounding factors
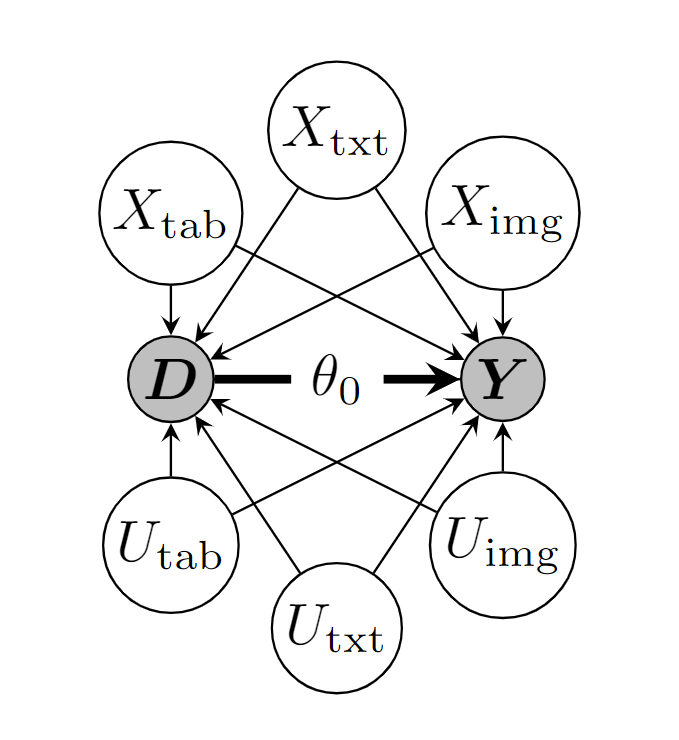
DAG for the semi-synthetic dataset. The confounding via the features \(X=(X_{\text{tab}}, X_{\text{txt}}, X_{\text{img}})\) can be adjusted for, whereas the unexplained/noise parts \(U=(U_{\text{tab}}, U_{\text{txt}}, U_{\text{img}})\) are unobserved.
Simulation Results - Performance of \(\hat{\theta}\)
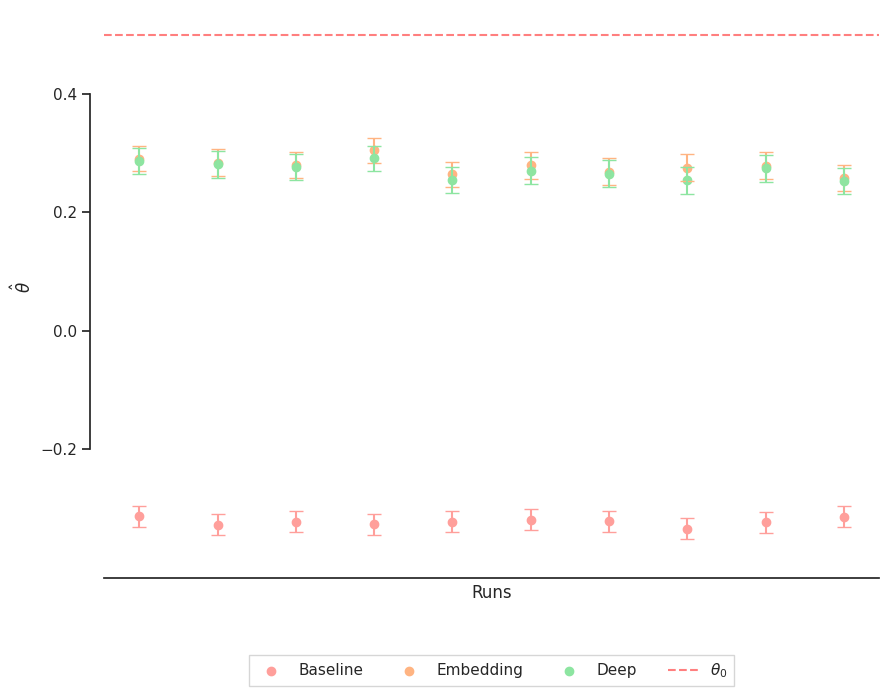
Boxplots of \(\hat{\theta}\). The Embedding Model and Deep Model have similar estimates. This indicates a stable and information-rich embedding \(H_E\), which provides a high explanatory contribution independent of the subsequent ML method for predicting \(Y\) and \(D\). \(\theta_0\) represents the upper bound.
Application: Estimation of Price Elasticity
- Understanding price elasticity is crucial for economic analysis and business decisions
- It influences strategies, pricing, and market dynamics
- Specifically in online marketplaces, unstructured data is available
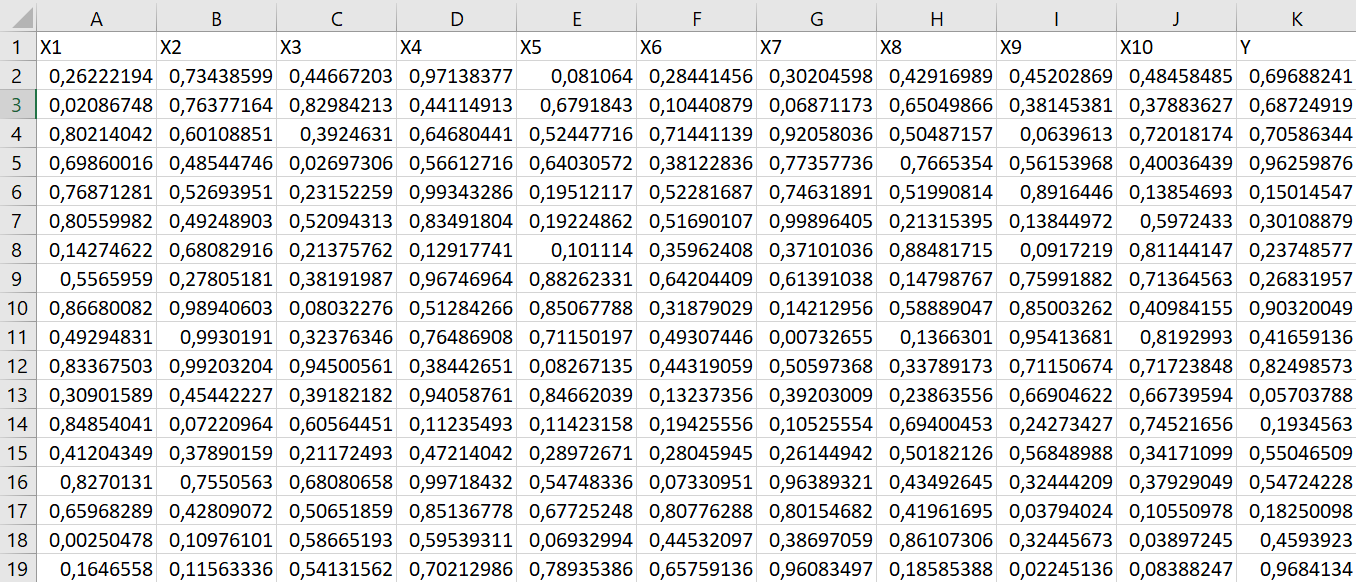
Amazon Toys Dataset
Continous Variables
- Reviews: Rating
- Reviews: Review Count
- New Offer Count: Current
- Count of retrieved live offers: New, FBA
- Count of retrieved live offers: New, FBM
Categorical Variables
- Lightning Deals: Upcoming Deal
- Buy Box: Is FBA
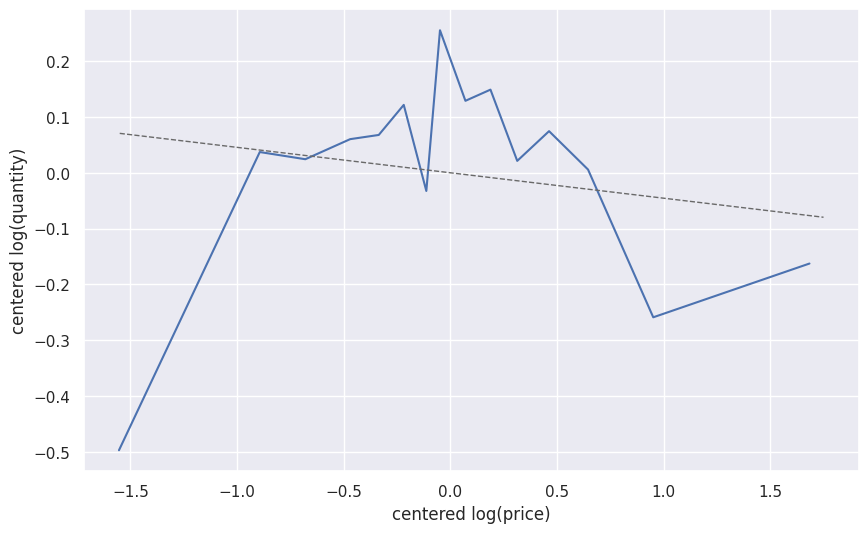
Scatterplots with OLS Regression of Tabular Variables and \(\ln(Q)\) 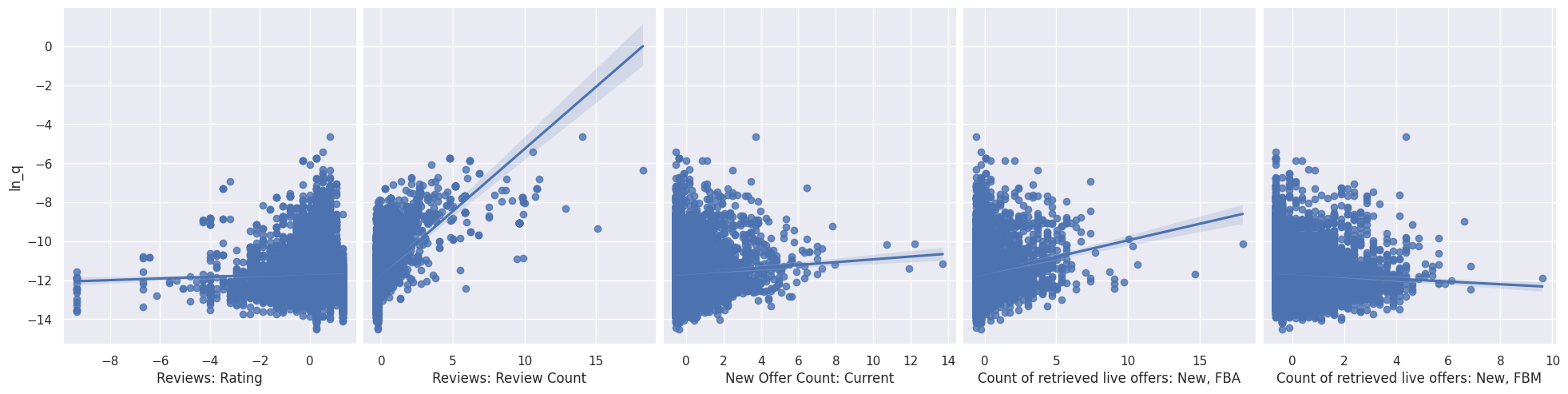
Model
- Run a simple log-log regression model
- Images and Text block backdoor path from price to demand (or sales rank)
\[ \ln(Q_{}) = \theta_0 \ln(P) + g_0(X) + \epsilon \]
\(\Rightarrow\) The causal parameter \(\theta_0\) can be interpreted as price elasticity of demand!
Baseline OLS Model
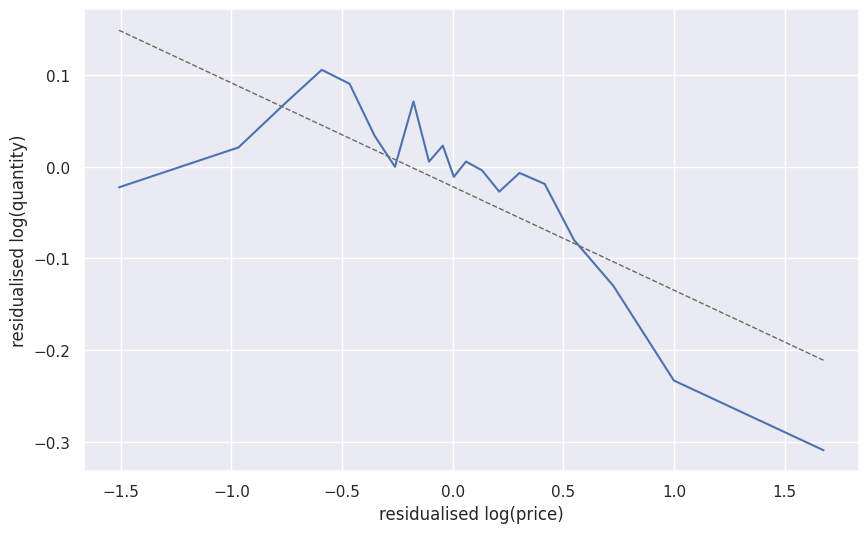
- Baseline estimate with tabular covariates \(X_{\text{tab}}\)
- OLS: \[ \begin{align*} \ln(Q) =&\ \theta_0 \ln(P) + \beta^T X_{\text{tab}} + \epsilon \end{align*} \]
- \(R^2 = 0.330\)
| 2.5 % | \(\hat{\theta}\) | 97.5 % |
|---|---|---|
| -0.072 | -0.046 | -0.019 |
Baseline DML Model
- Estimate with tabular data as covariates \(X_{\text{tab}}\) in \(\texttt{DoubleMLPLR}\) model with \(\texttt{RandomForest}\) regressors
- \(l_0(X_{\text{tab}}) := \mathbb{E}[\ln(Q)|X_{\text{tab}}]\)
- \(R^2_{l_0} = 0.5986\)
- \(m_0(X_{\text{tab}}) := \mathbb{E}[\ln(P)|X_{\text{tab}}]\)
- \(R^2_{m_0} = 0.1884\)
- \(l_0(X_{\text{tab}}) := \mathbb{E}[\ln(Q)|X_{\text{tab}}]\)
| 2.5 % | \(\theta\) | 97.5 % |
|---|---|---|
| -0.132 | -0.1098 | -0.080 |
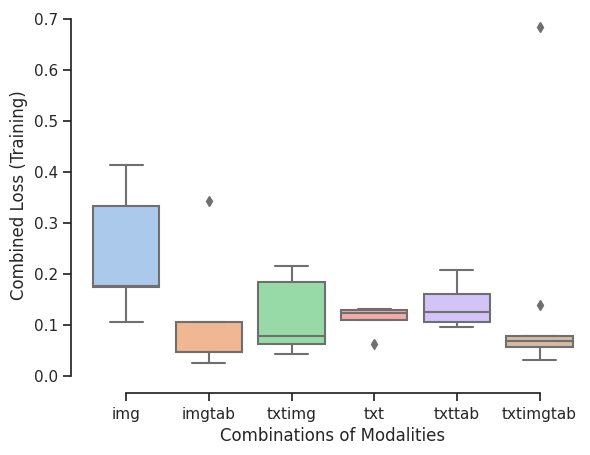
Deep Learning Models: RMSE-Scores
- Combined RMSE Score (Training)
- Combined RMSE Score (Validation)
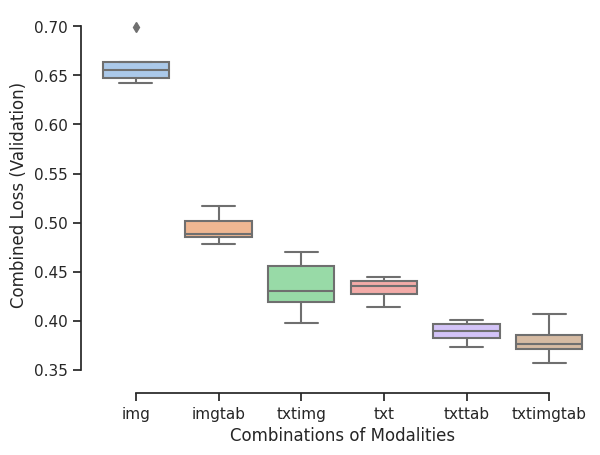
Deep Learning Models: \(R^2\)-Scores
- \(R^2\) of log(Quantity) on Validation Set
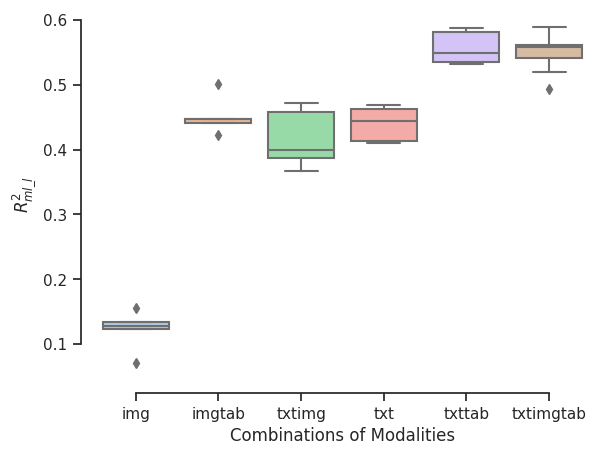
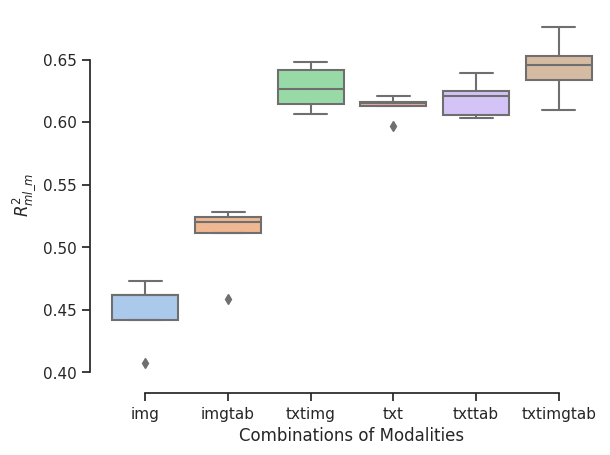
- \(R^2\) of log(Price) on Validation Set
(First) Results
- Using different combinations of tabular, image and text data we obtain the following estimates
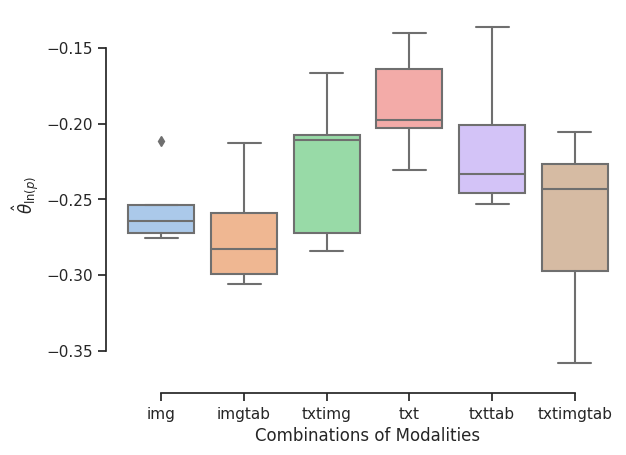
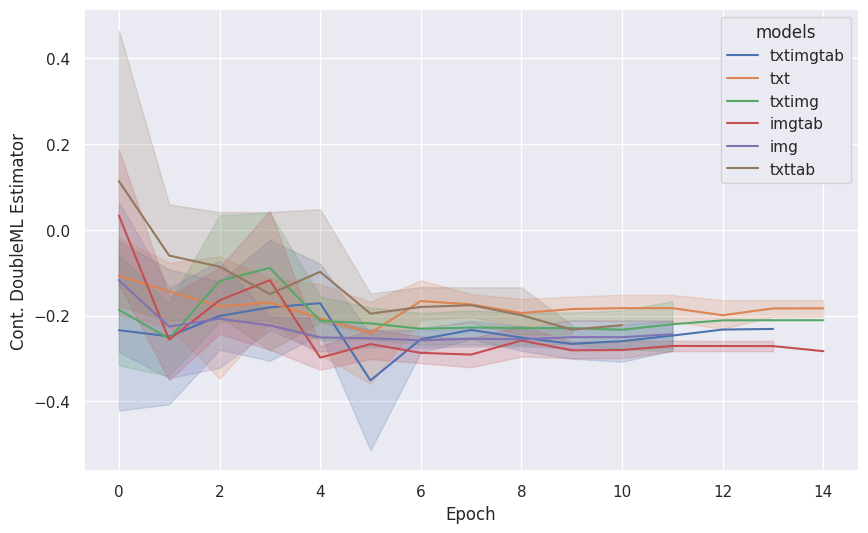
Comparison to Baseline Estimates
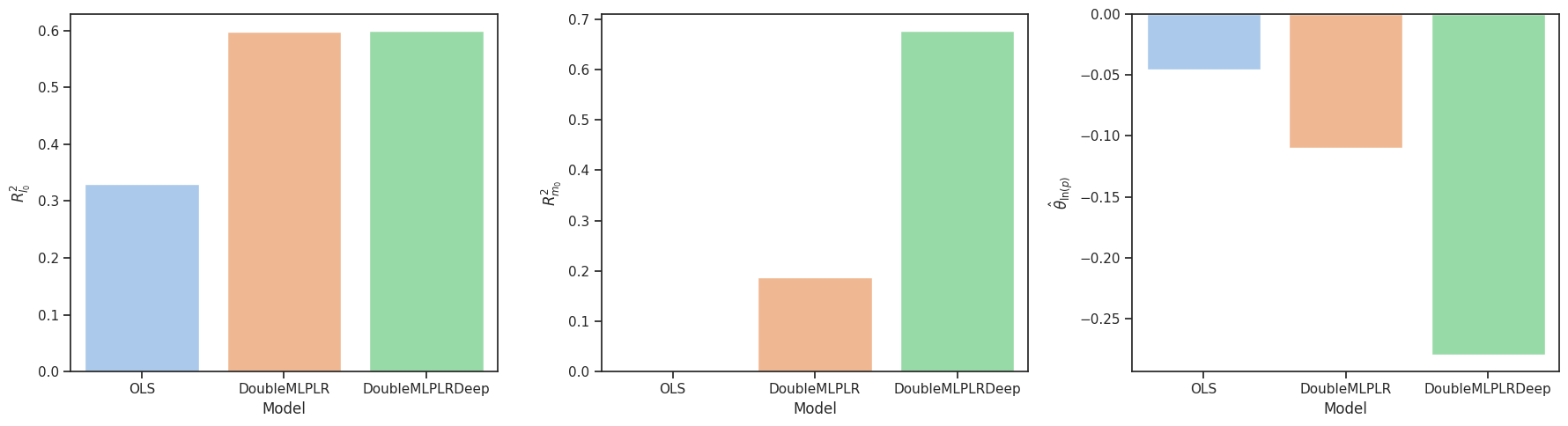
| Model | Covariates | \(R^2_{l_0}\) | \(R^2_{m_0}\) | \(\hat{\theta}_0\) |
|---|---|---|---|---|
| \(\texttt{OLS}\) | \(X=X_{tab}\) | \(0.3300\) | - | \(-0.0455\) |
| \(\texttt{DoubleMLPLR}\) | \(X=X_{tab}\) | \(0.5986\) | \(0.1884\) | \(-0.1098\) |
| \(\texttt{DoubleMLPLRDeep}\)1 | \(X=(X_{tab}, X_{txt}, X_{img})\) | \(0.5990\) | \(0.6765\) | \(-0.2794\) |
More on Double Machine Learning
Thank you!
GitHub Repository

Contact
In case you have questions or comments, feel free to contact me
Amazon Toys Dataset
Data Examples
Kinsmart Set of 4 McLaren 720s Toy | … 
Pixar Cars Mack Uncle Lightning… 